Upgrade a cluster
Upgrade a Cluster
Context
In order get a new release on the control plane components and the worker nodes, they need to be updated via the UI.
Please note that control plane components and worker nodes have different lifecyles.
Prerequisites
In order to upgrade a cluster, you need to have an existing MetaKube cluster which does not have the latest release for control plane components or worker nodes.
Upgrade control plane
When an upgrade for the control plane is available, an upwards arrow (↑) will be shown besides the control plane version:
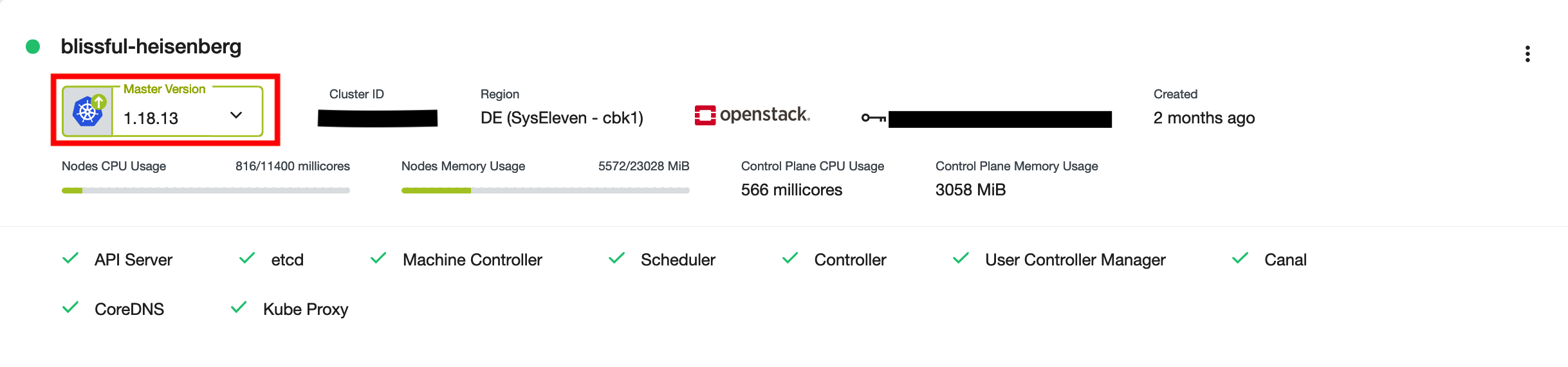
To start the upgrade, just click on the arrow and choose the desired version (most recent, tested version is selected):
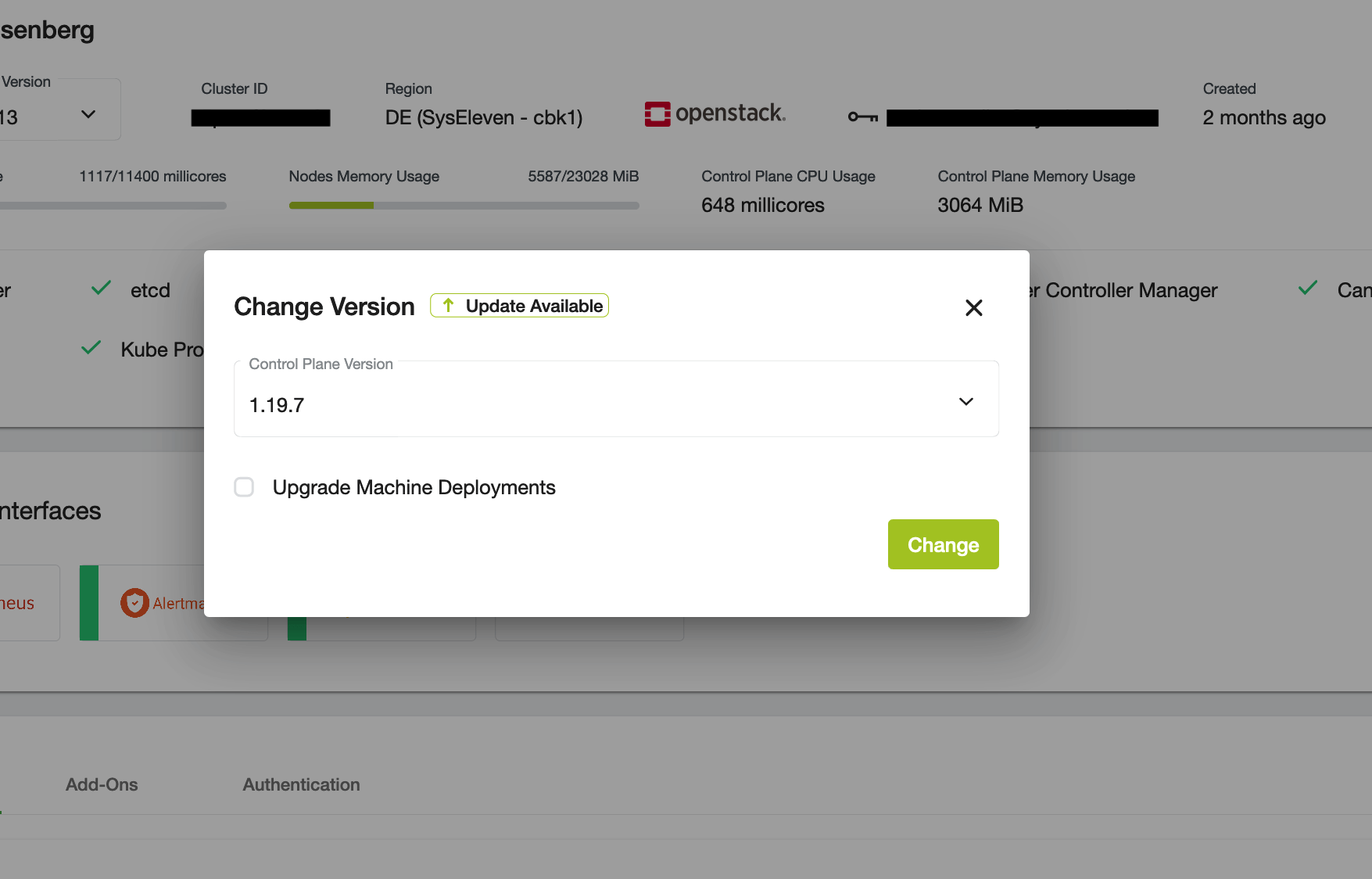
After the update is initiated, the control plane components will be upgraded in the background. All newly created worker nodes will be installed with the new version, but existing nodes will not be changed. Refer to the next chapter on how to upgrade your existing worker nodes.
Upgrade worker nodes
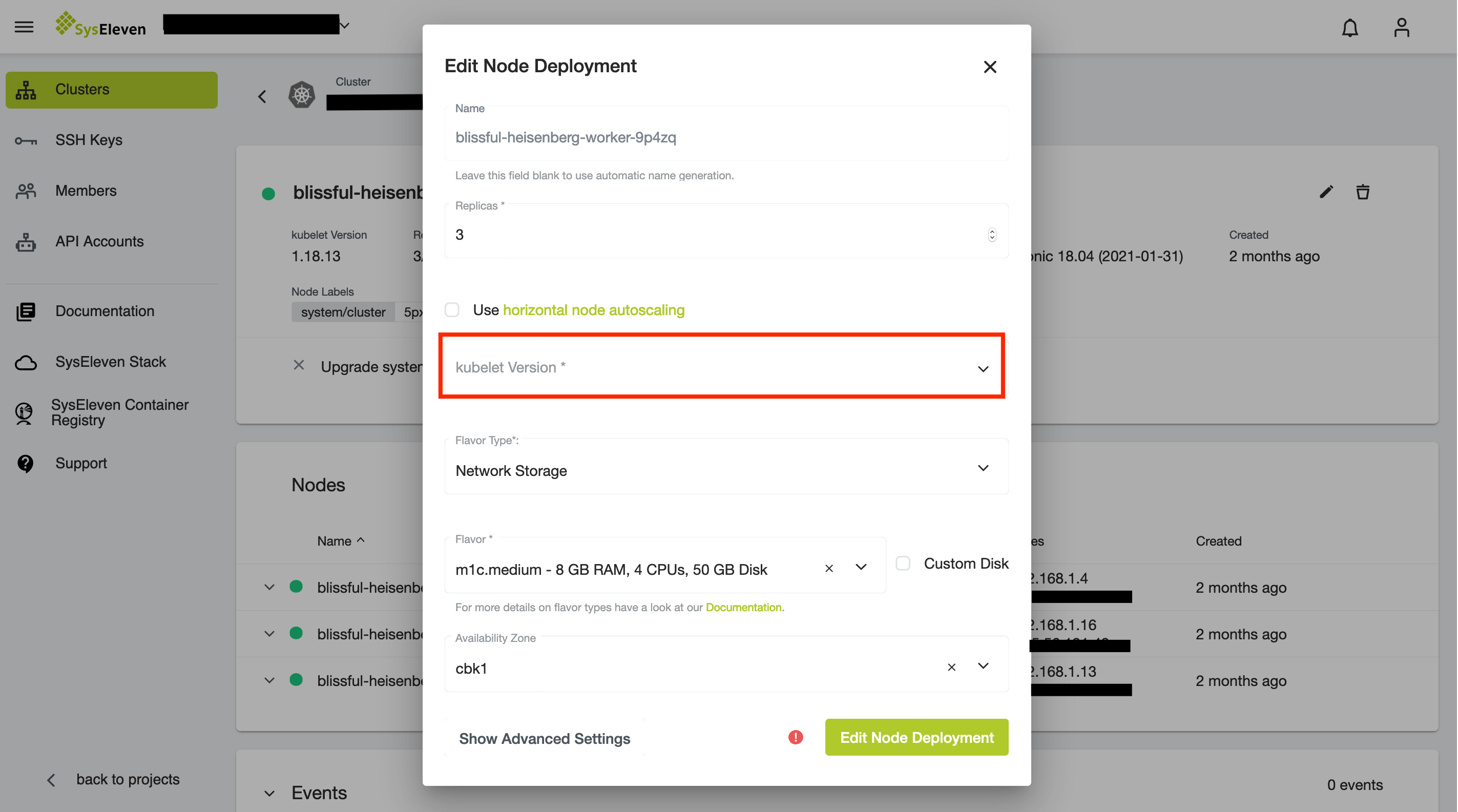
When you want to upgrade your worker nodes you can easily edit your node deployment for the active cluster and MetaKube will take care of the updates. To do so, hover over the node deployment and click the edit button or open the node deployment overview and click on the Edit button to change its settings:
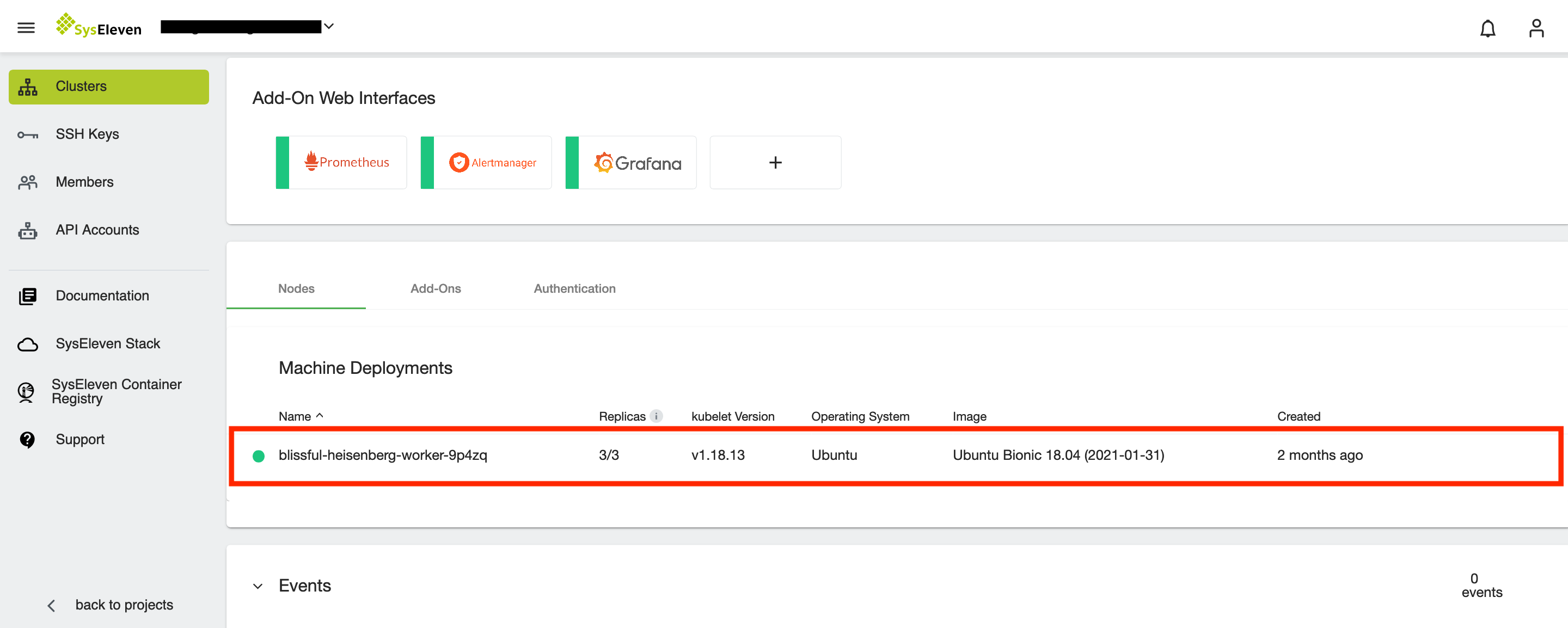
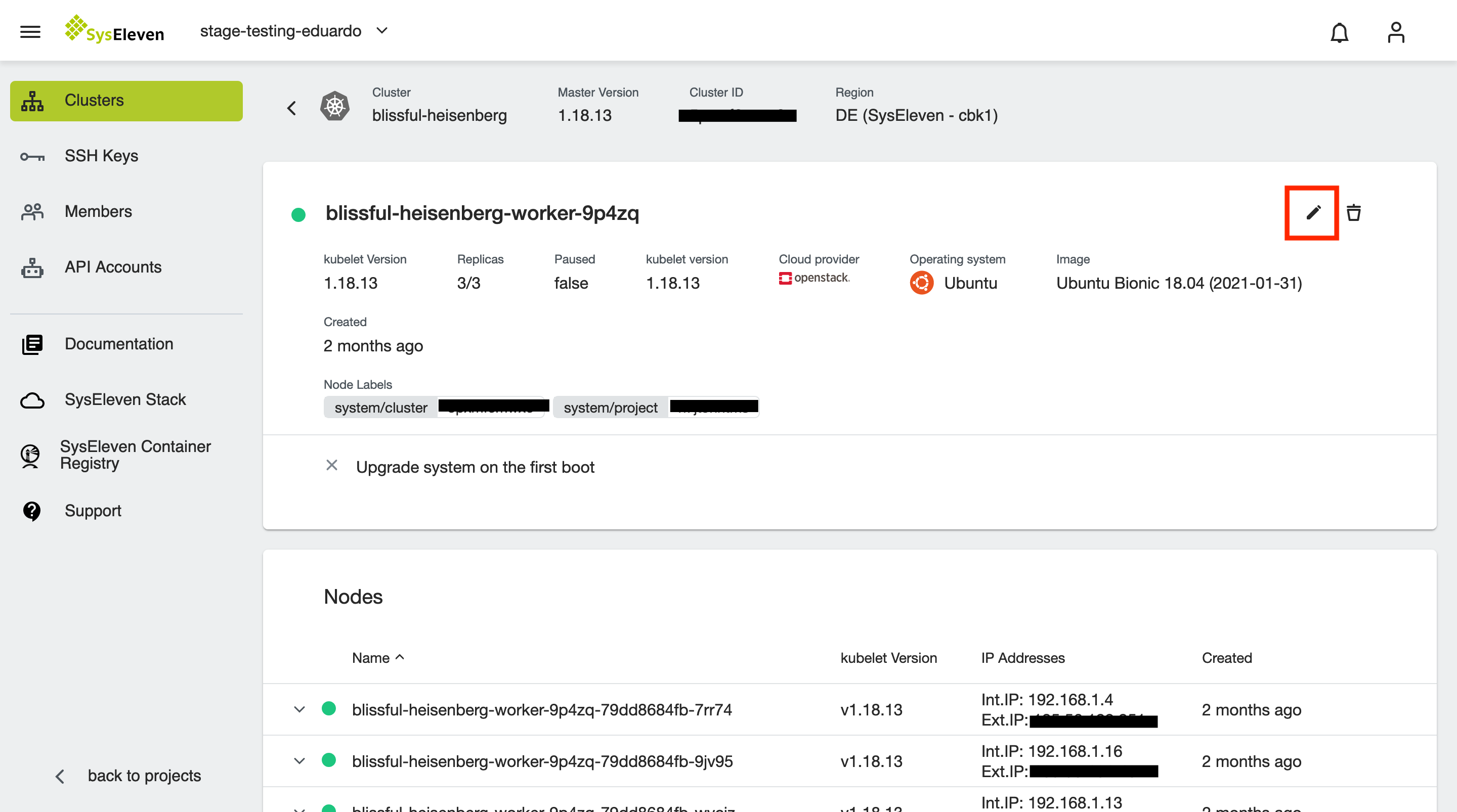
This will open a popup where you can choose the to be installed Kubernetes version:
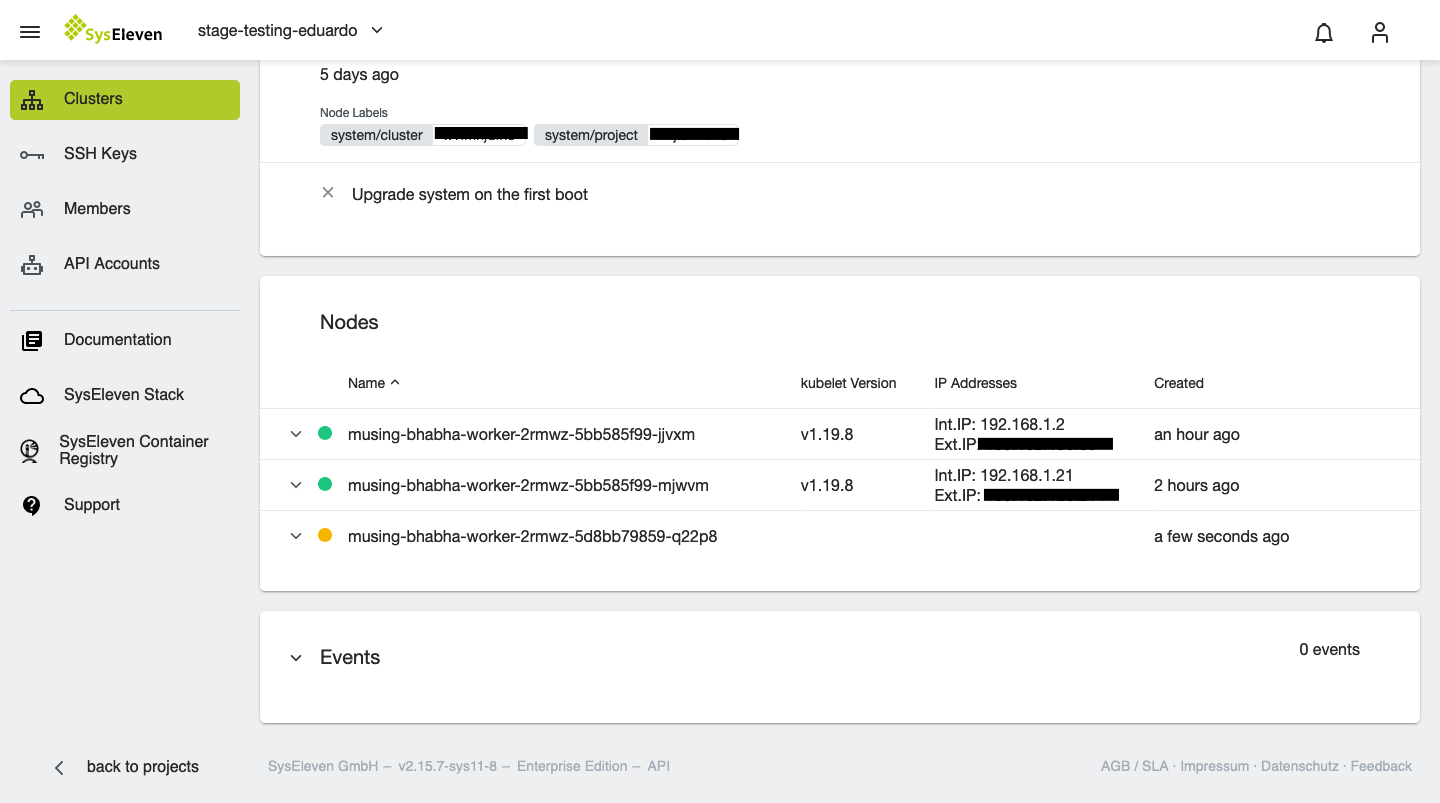
Your worker nodes will now be updated one by one:
Downgrade a cluster
You can also downgrade a cluster to any older patch version of the same minor version, by clicking on the version number of the cluster on the cluster detail page.
Validation
Check the current version either in the UI or via console command.
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
tutorial-5bd864df7c-hvbkl Ready <none> 63m v1.23.8
tutorial-5bd864df7c-hztvf Ready <none> 63m v1.23.8
tutorial-5bd864df7c-x586s Ready <none> 63m v1.23.8Clean-up
There is no clean-up for this tutorial, because you will need this for all further tutorials.